HashMap和ConcurrentHashMap
HashMap
根据键的hashCode值存储数据,非线程安全。
如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
存储结构
数组+链表+红黑树(JDK1.8增加了红黑树部分)
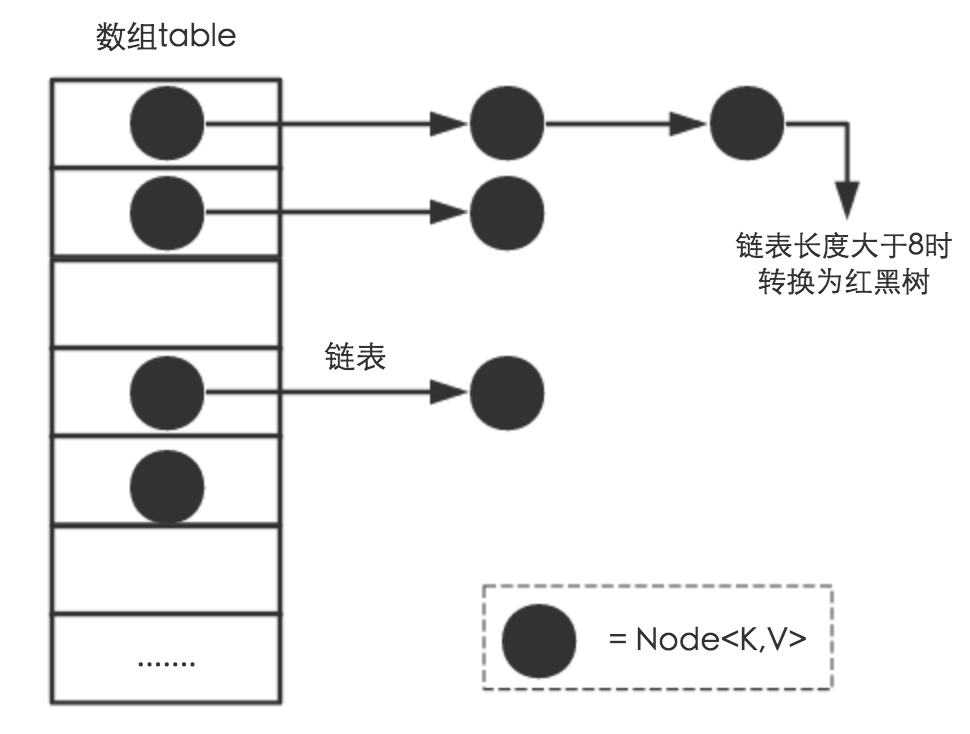
Node对象:Node<K,V>
哈希桶数组:Node[] table
Node[] table的初始化长度length(默认值是16);Load factor为负载因子(默认值是0.75);
threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。
threshold = length * Load factor
根据key获取哈希桶数组索引位
希望元素位置尽量分布均匀一些
源码如下:
1 | 方法一: |
取key的hashCode值
高位运算
hashCode()的高16位异或低16位实现
- 数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销
取模运算
把hash值对数组长度取模运算,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,所以改用方法二来实现取模运算
- 在HashMap中,哈希桶数组table的长度length大小必须为2的n次方
h& (length-1)运算等价于对length取模,&比%具有更高的效率

put方法
- 判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。
- 根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。
- 如果当前桶有值( Hash 冲突),那么就要比较当前桶中的
key、key 的 hashcode与写入的 key 是否相等,相等就赋值给e,在第 8 步的时候会统一进行赋值及返回。 - 如果当前桶为红黑树,那就要按照红黑树的方式写入数据。
- 如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。
- 接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。
- 如果在遍历过程中找到 key 相同时直接退出遍历。
- 如果
e != null就相当于存在相同的 key,那就需要将值覆盖。 - 最后判断是否需要进行扩容。
扩容机制
JDK1.7 重新申请一个2倍大小的数组,然后把旧数据transfer到新的数组上去,重新计算hash,会倒置
1 | void transfer(Entry[] newTable, boolean rehash) { |
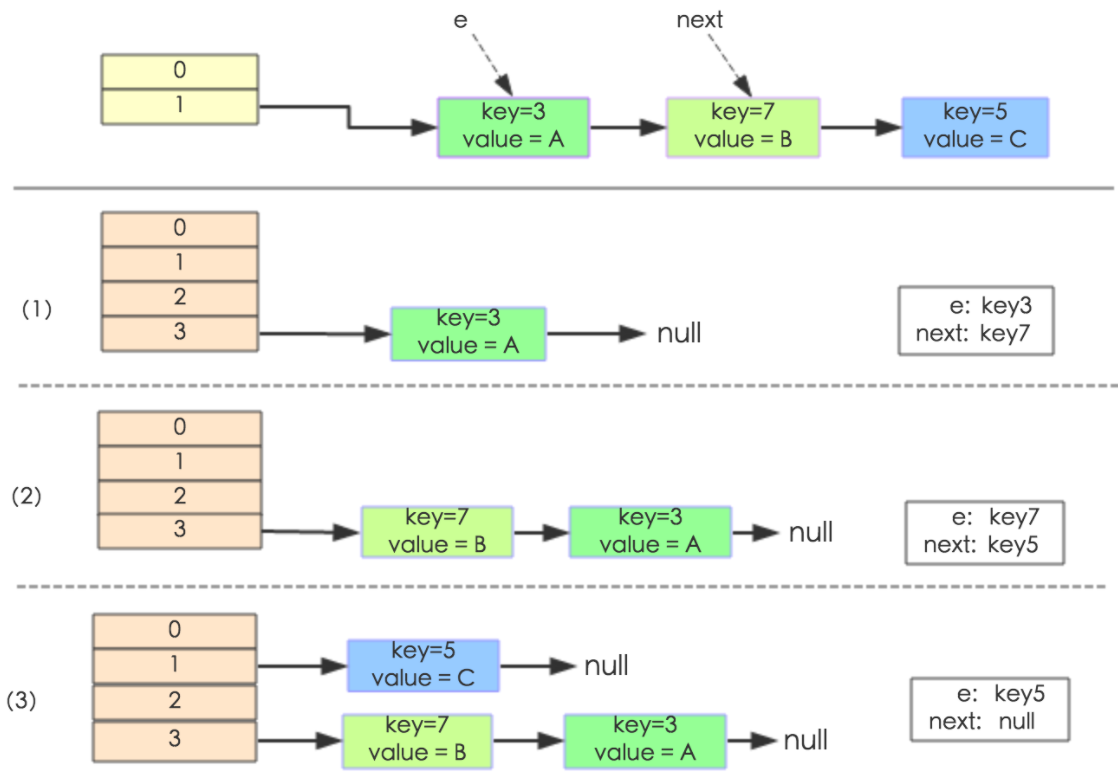
成环问题:
两个线程同时要resize扩容时,第一个线程完成后会倒序(原来A->B,变为B->A),此时第二个线程执行e.next = newTable[i]; 时,就会把A(e)连到B(newTable[i])上,即形成了A到B的循环。
JDK1.8
由于table长度是2次幂,所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置
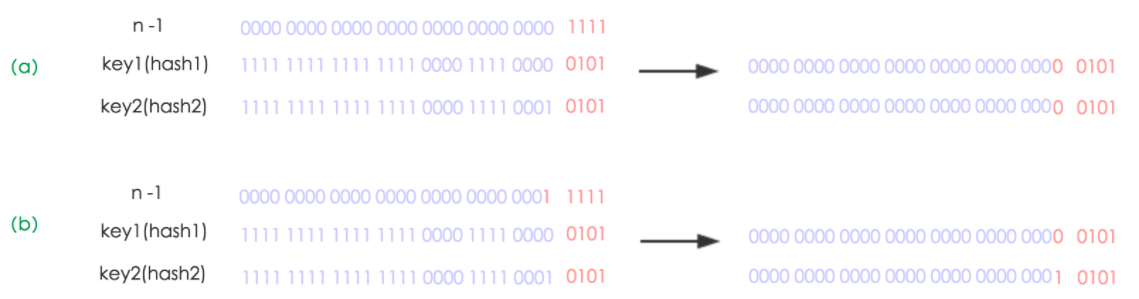
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
即原来链表上的节点按照高位0和1分裂成两个链表,一个链表留在原来的位置,另一个链表移动到原来位置+2次幂位置。因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”
既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了
线程不安全
JDK1.7扩容时由于倒置,多线程会导致链表里产生环,当查找一个不存在的元素时就会死循环
当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。
JDK1.8 没有倒置了,不会死循环,但仍然会丢失数据
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
ConcurrentHashMap
JDK1.7
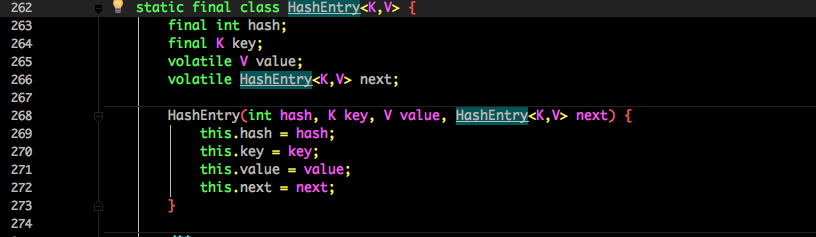
结构如下:segment相当于哈希桶数组Table,HashEntry相当于1.8的Node
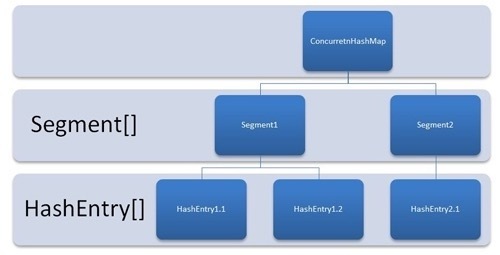
HashEntry :
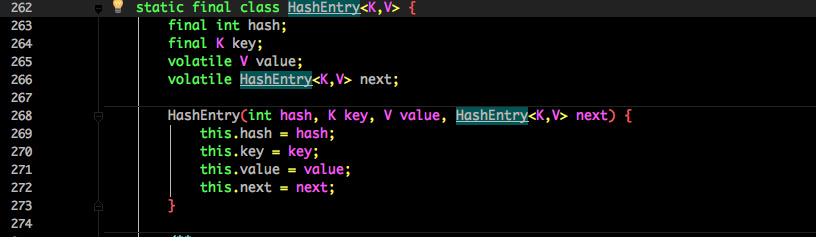
核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性
原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
put 方法
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理
1 | public V put(K key, V value) { |
- 通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put
1 | final V put(K key, int hash, V value, boolean onlyIfAbsent) { |
- 先尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用
scanAndLockForPut()自旋获取锁 - 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value
- 不相等则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容
- 最后会解除在 2 中所获取当前 Segment 的锁
scanAndLockForPut()
1 | private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { |
- 尝试自旋获取锁。
- 如果重试的次数达到了
MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功。
get 方法
只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上,整个过程都不需要加锁
JDK1.8
1.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题:查询遍历链表效率太低
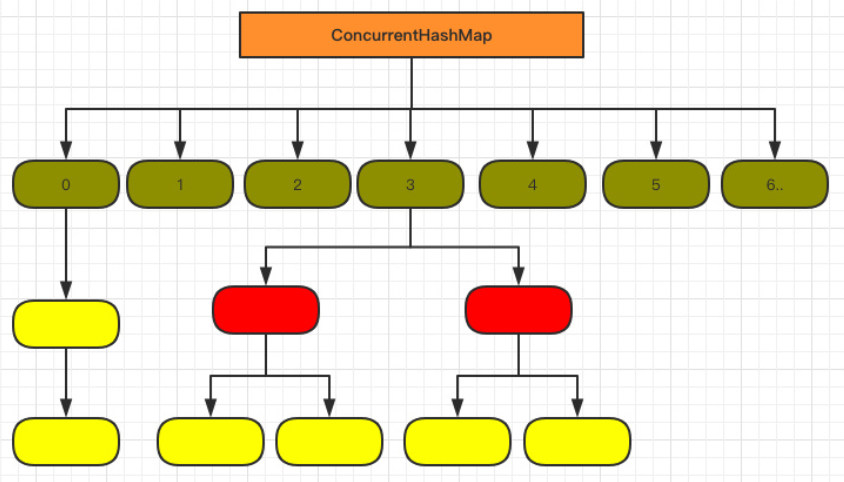
结构:
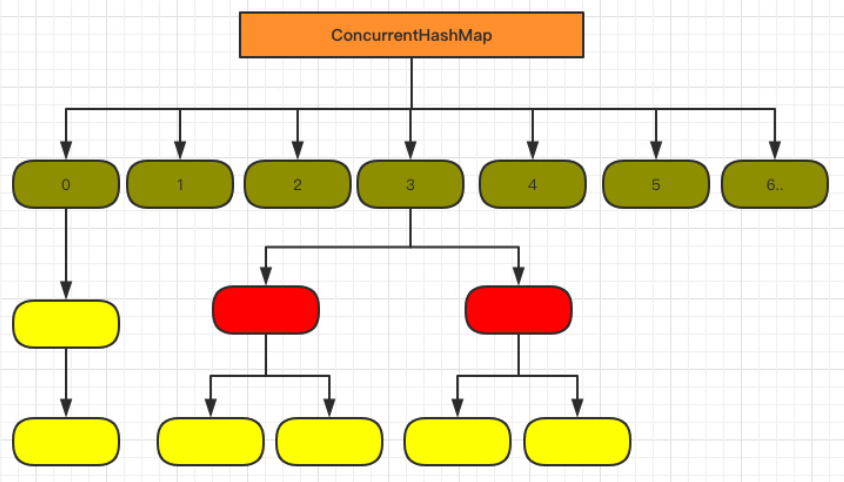
抛弃了原有的 Segment 分段锁,而采用了
CAS + synchronized来保证并发安全性HashEntry 改为 Node
put 方法
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
f即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树。
get 方法
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值
总结
1.7主要用分段锁技术,Segment继承于ReentrantLock。每个线程占用锁访问一个Segment时,其他Segment不受影响。
1.8采用CAS+synchronized保证并发安全性,红黑树优化查询效率。










